Experiment Length:
Estimated Time: 1 week
Actual Time: 1 week
Summary:
The purpose of this test is to test independent changes to model, system prompt, prompts, fine-tuning, and other methods and resulting dependent effects on reasoning capabilities. We’re using GS8MK and testing on only the last 100 problems of the test set because money.
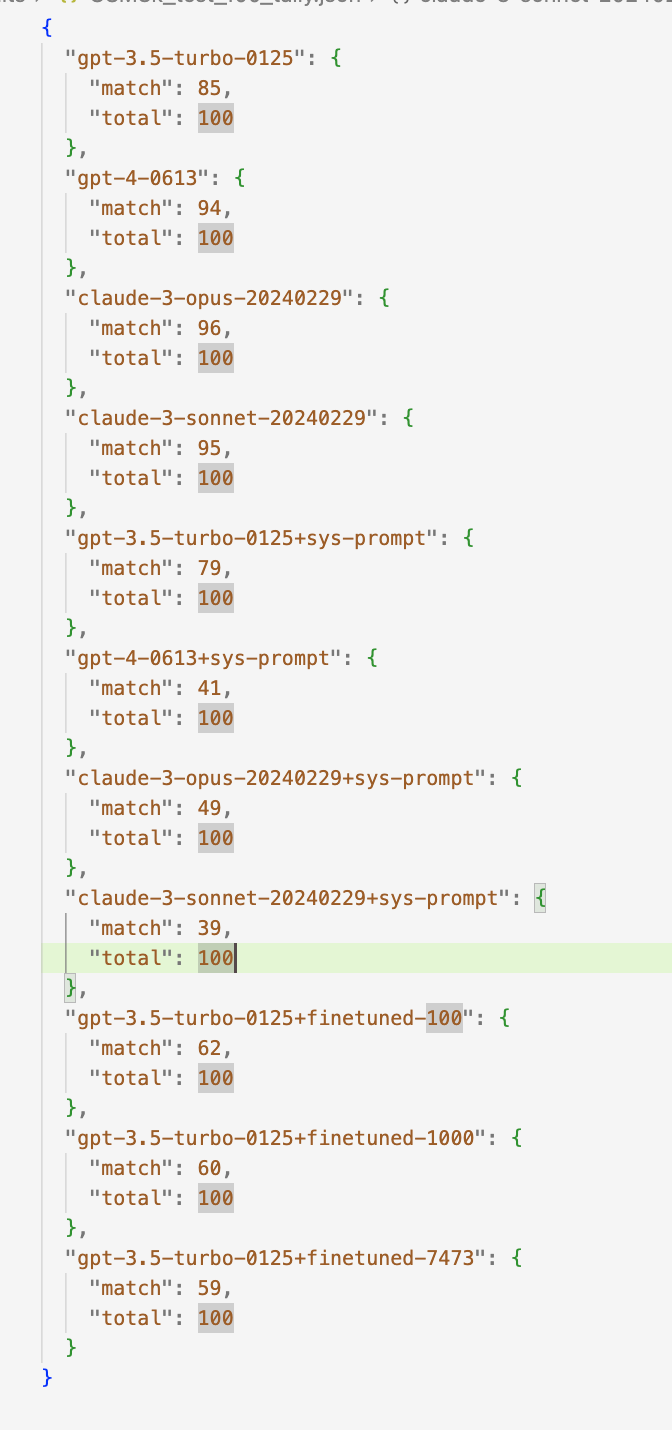
This tests 11 approaches:
- gpt-3.5-turbo-0125
- gpt-4-0613
- claude-3-opus-20240229
- claude-3-sonnet-20240229
- gpt-3.5-turbo-0125 with system prompt
- gpt-4-0613 with system prompt
- claude-3-opus-20240229 with system prompt
- claude-3-sonnet-20240229 with system prompt
- gpt-3.5-turbo-0125 fine-tuned 100
- gpt-3.5-turbo-0125 fine-tuned 1000
- gpt-3.5-turbo-0125 fine-tuned 7473
Plan:
Method:
The experiment was conducted using Python and the Poetry package management tool, with the GSM8K dataset serving as the primary source of data.
Here’s a sample from GSM8K:
{
"question": "Janet\u2019s ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. She sells the remainder at the farmers' market daily for $2 per fresh duck egg. How much in dollars does she make every day at the farmers' market?",
"answer": "Janet sells 16 - 3 - 4 = <<16-3-4=9>>9 duck eggs a day.\nShe makes 9 * 2 = $<<9*2=18>>18 every day at the farmer\u2019s market.\n#### 18"
}
For those with system prompts, we used the same prompt:
SYSTEM_PROMPT = """<DESCRIPTION> You are post-graduate mathematics student at MIT working on the side to answer and grade some math questions. This is a preliminary test to see how you do! Answer to the best of your ability. </DESCRIPTION>
<HOW_TO_RESPOND> Respond with a SINGULAR number, the answer to the computation question. For example, respond with only: "53", "0", "-1203923" </HOW_TO_RESPOND>
"""
Evaluation Plan:
- Dependent Variable (DV): Performance on GSM8K
- Independent Variables (IV): Variations on model, system prompt, and fine-tuning
- Task: Models and their variants were run to observe performance differences.
- Threats: The limited dataset, specifically the last 100 examples of GSM8K, was a potential constraint.
Result: 🟢 Pass
Completed it!
Claude-3-Opus marginally had the best performance among the tested models.
- Claude-3-Opus-20240229 achieved a score of 96/100.
- GPT-4-0613 followed closely with a score of 94/100.
- GPT-3.5-Turbo-0125 scored 85/100.
Interestingly, the addition of system prompts or fine-tuning generally resulted in reduced performance across the models.
What I Learned:
Claude-3-Opus emerged as the slightly leading model.
I also learned that - surprise! - mindlessly adding system prompts and fine-tuning doesn’t always help much. These changes do not always translate into expected performance increases and may sometimes detract from the model’s effectiveness on specific tasks.
Done in collaboration with Justin Lin!
This post was generated by running my experiment notes through ChatGPT.