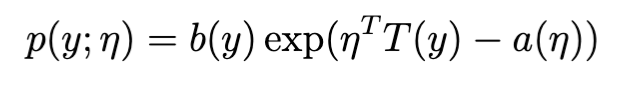#concept-pamphlet #class #todo go through the entire CS229 lecture notes and UPDATE my definitions of various terms. please 🙏🏻 important to do before school starts
Linear regression
What is the notation for a training set?
Incudes training example with input and output features
?
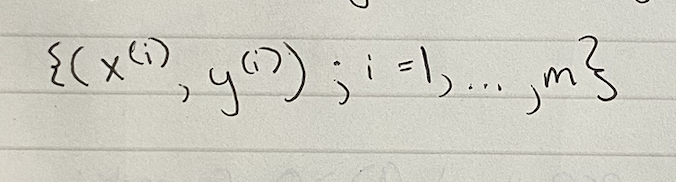 Note that the superscript “(i)” is simply an index / i-th item in the training set and has nothing to do with exponentiation.
Note that the superscript “(i)” is simply an index / i-th item in the training set and has nothing to do with exponentiation.




What are the benefits of squaring something like in the cost function of the ordinary least squares regression model?
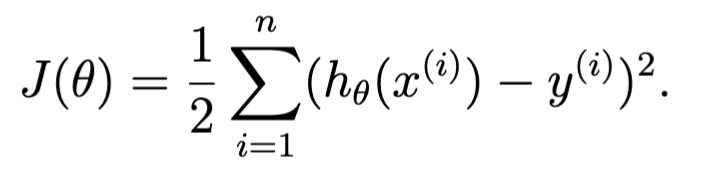 ?
?
- The result of the square is always positive
- Squaring puts more weight on larger errors/differences
- The result is always differentiable
- The result corresponds to the assumption of normally distributed errors
What is the least-squares cost function J?
?
What is learning rate, in the context of training neural nets? In gradient descent?
?
A hyperparameter that determines the size of steps taken during gradient descent. A higher learning rate might converge faster but overshoot the minimum, while a lower rate converges more slowly but reliably
In the context of gradient descent, it is α:
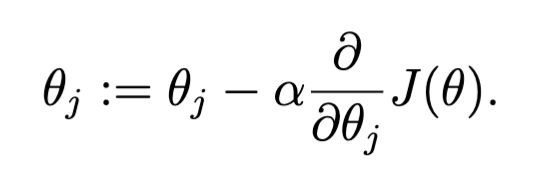
What is the equation for gradient descent?
?
where J is the cost function and α is learning rate.
Or this for a single training example:
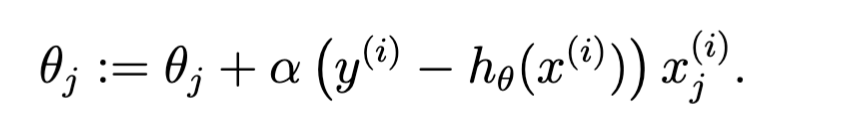
What is the difference between stochastic gradient descent and batch gradient descent?
What is the likelihood function?
What is the log likelihood function?
What is the maximum likelihood function?
i don’t understand: LMS update rule / Widrow-Hoff learning rule and how that was derived
Classification and logistic regression
perceptron learning algorithm
Newton’s method - for finding a zero of a function
hessian
fisher scoring
Generalized linear models
A class of distributions is in the exponential family if it can be written in the form: