#concept-pamphlet #todo: finish vid and notes
Terms
- tokenize
- tensor
- (B, T, C) tensor
- logits
- attention
- bag of words
- QKV
- softmax function
- dot product
- encoder
- decoder
- positional embeddings
- embedding layer
- input embeddings
- negative log likelihood
- bigram
- multinomial
- bigram
- hyperparameter
- optimization
Processes
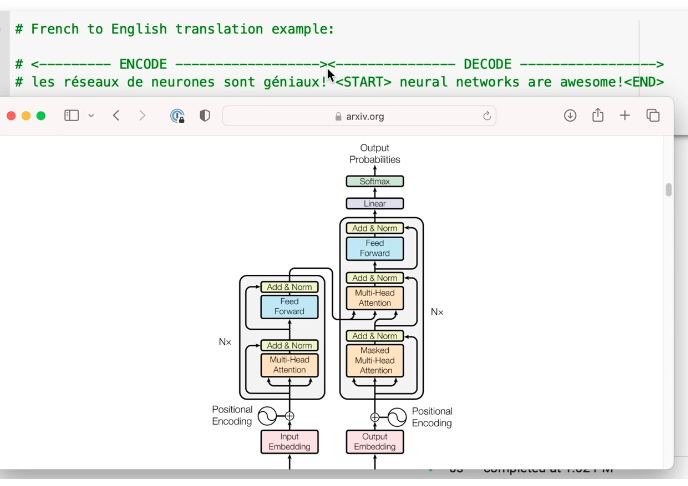
Attention is all you need

GPT-2 Paper
- strengths?
- weaknesses?
Notes
- 124m, 12 layers, 768 channels
wte = token embedding. also, output embedding wpe = positional embedding h.0, h.1…h.1 = hidden layers. 12 ln_f = normalization layer lm_head = linear
- 50257 tokens
- 768 embedding size
tiktoken >> is a fast open source BPE tokeniser
What five fields for GPT config? ? block_size, vocab_size, n_layer, n_head, n_embd
- block_size: int = 1024 # max sequence length
- vocab_size: int = 50257 # number of tokens: 50,000 BPE merges + 256 bytes tokens + 1 <|endoftext|> token
- n_layer: int = 12 # number of layers. Each layer consists of a self-attention mechanism and a feedforward neural network.
- n_head: int = 12 # number of attention heads. Multi-head attention allows the model to attend to different parts of the input sequence simultaneously.
- n_embd: int = 768 # embedding dimension. Each token in the input sequence is mapped to a dense vector of size n_embd.
Tokenizer encoding/decoding is reminiscent of human memorization techniques like ____ >> PAO
Say for example that we have a corpus of Shakespeare’s texts and we want to train a GPT-2 like model to output Shakespeare-like text. How do you convert this text into training data? 2 steps:
_____- turn into training data: key-value pairs where key is a chunk of
block_size, and value is the target is the next token ?
tokenize it
?
tokenize it
- some modes will be different based on training vs. inference. For ex, whether to drop layers
scaled dot product attention equation ?
In general, attention mappings can be described as a function of a query and a set of key-value pairs.
How does attention work in a transformer with QKV?
- Attention scores computed between a
___and all____, usually using dot product. These scores tell how much attention to put on corresponding outputs - Scores are passed through softmax to
______into probabilities - Output of attention mechanism is the weighted sum of the Values, where the weights are the normalized attention scores ? Query, Keys, normalize
References
- Karpathy’s GPT video
- Attention is All You Need paper
Supplementary materials
neural networks - visual guide to transformers part 1: https://www.youtube.com/watch?v=dichIcUZfOw part 2: https://www.youtube.com/watch?v=mMa2PmYJlCo part 3: https://www.youtube.com/watch?v=gJ9kaJsE78k
more notes
GPT-2 is a decoder only model
Layer normalization - add and norm is before rather than after in gpt-2. There’s one more norm at the end
Visualize transformer architecture
Nn.embedding - fancy wrapper around single array of numbers
GPT class wte- token embeddings Wpe h Ln_f Lm_head
Memorize