2x+ Retention Improvements to Human Long-Term Memory
Experiment Length
Estimated Time To Build: 3 months
Summary
Today the average person does not have a structured explainable database within their own mind, and collectively humans lack the type of database that can be augmented by fellow humans’ and computers’ databases in an scalable and explainable manner. This applies both to short-term and long-term memory.
From my personal experience, it seems that a combination of some human memory techniques across history and basic computer data structure knowledge could increase the following by 2x+:
- Human long-term memory retention of text
- Human memory retrieval speed and accuracy of text
Though the below are harder to measure, it seems likely that these protocols will also aid in:
- Space efficiency of human memory storage
- Augmentation of a person’s learning, retention, and recall alongside a computer or AI system
In this proposal, I’ll discuss isomorphic data structures shareable between combinations of human and machine long-term memory. The main components are: a computer memory schema, a human memory schema, and a protocol for the interaction of any of the 3 combinations of schemas.
Hopefully, with this memory schema established, a person can then augment their learning, retention, and recall with a set of LLMs that generate material following the schema, based on some reputable source material.
Related Works
There are old techniques to improve human short-term and long-term memory used by memory experts today
Memory techniques with and without referencing an external object have been independently developed across the world, from England to the Polynesian Islands. These memory techniques include pegs, memory palaces, and lukasa boards. From my personal experience and from anecdotes online, techniques tend to be more effective if they are multimodal, including visual, spatial, kinesthetic, and audio representations. Compelling narratives and unique visualizations also seem to improve efficacy.
Today, memory techniques are most widely used in professions like medicine that require a lot of memorization. They’re also used in memory competitions or to pass down oral history in groups like the Aboriginal Australians.
An anecdote: Surviving medical school by using method of loci
My brother is a resident orthopedics surgeon who used augmented method of loci to get through his board exams. In medical school, he used memorize about 4,000 concepts using this software tool Sketchy that maps medical concepts to whacky visualizations.
Apparently, thousands of medical students every year use Sketchy. Here is an example of one of their scenes that is used for USMLE prep:

What is even more wild is that many of his medical peers have all of these weird scenes etched into their brains, from their time in medical school.
Supposedly, Sketchy touts that 96% of their students have higher exam scores. [15]
There are probably many more ways to optimize memory techniques past what Sketchy does. For reference, world record holders for memory competitions can respectively memorize 630 digits in 5 minutes, 224 people’s names in 15 minutes, or 7,485 binary digits in 30 minutes. [16] Neuroscientists have also observed that the world’s best memorizers do not have different brains from the average person’s, but rather it was their use of techniques such as the method of loci that led to substantially improved memorization abilities. [19]
Spaced repetition
Spaced repetition is a complementary tool with memory palaces to retain memorizations long-term, by utilizing Ebbinghaus’ forgetting curve.
Limitations of these memory techniques include distracting or meaningless images, as well as inefficient methods that encode the same information in multiple modalities or symbols.
Analogy between CRUD operations and human memory
Computer or human memory can roughly be broken down into: encoding, storage, and retrieval of information. [17] From an educational lens, these are also called: learning, retention, and recall of knowledge.
The fundamental data operations of a REST API are CRUD: CREATE, READ, UPDATE, and DELETE. The first half of CRUD is most similar between human and machine memory:
- CREATE :: Encoding :: Learning
- READ :: Retrieving :: Recall
Admittedly, the analogy breaks down with the methods of UPDATE and DELETE. For UPDATE, it seems like memory is updated for humans in concurrence with learning and recall. For DELETE, it also seems like a person cannot consciously choose to delete a single memory.
Another difference is that CRUD can be built to be quite reliable for computers. For example, if I store a key-value pair of ( favorite_fruit, mango ) then READ with the query favorite_fruit will always return mango, until I call UPDATE. Human memory is a bit messier than that!
Implementation Plan: A shared schema between mutually explainable human memory (MEHM) and mutually explainable computer memory (MECM)
Definitions
Let’s define a few terms first:
- Loops: Processes that lead back to themselves.
- Level-crossing: Loops that cross layers.
- Strange Loops: Level-crossing processes that lead back to themselves.
- Isomorphism: A mapping or correspondence between two structures in such a way that each element in one structure has a corresponding element in the other structure. [18]
- Keyword: a string used to access a specific human memory structure.
- Explainable: An adjective to describe a concept that can be stored and retrieved in a similar enough format. It is similar enough based on the concept’s domain and the retriever’s objective(s), memory capabilities, and the external tools they have at their disposal for the objective(s).
- Mutually explainable (ME): a concept that is explainable to both humans and computers. For a more precise definition, we consider a concept to be explainable if it can be understood either by any college-educated American in 2024 or computed by a 15-inch M2 chip 2024 Macbook Air.
Design considerations
Assume the following are traits shared by both human and computer data structures in this configuration:
- Nodes are accessible by keywords
- Recursively decomposable
- Uniquely, recursive decomposability means theoretically infinite higher and lower levels. For integers:
- Level 0 = base
- Levels [-infinity, -1] = higher levels
- Levels [1, infinity] = lower levels
- Version history
- Annotatable base
- Multimodal
- Uses memory techniques that balance needs for space efficiency, speed of learning and retrieval, within the context of some objective
- Decision-making mechanism for prioritizing knowledge to store is based on (1) observable truth, (2) credibility, (3) useful outcomes
- Reduce loss between combinations of human and machine schemas
- Deterministic finite automata with version control?

Pseudocode for finding a loci in a recursively decomposable memory structure
Schemas
Consider the following schemas for Mutually Explainable Memory:

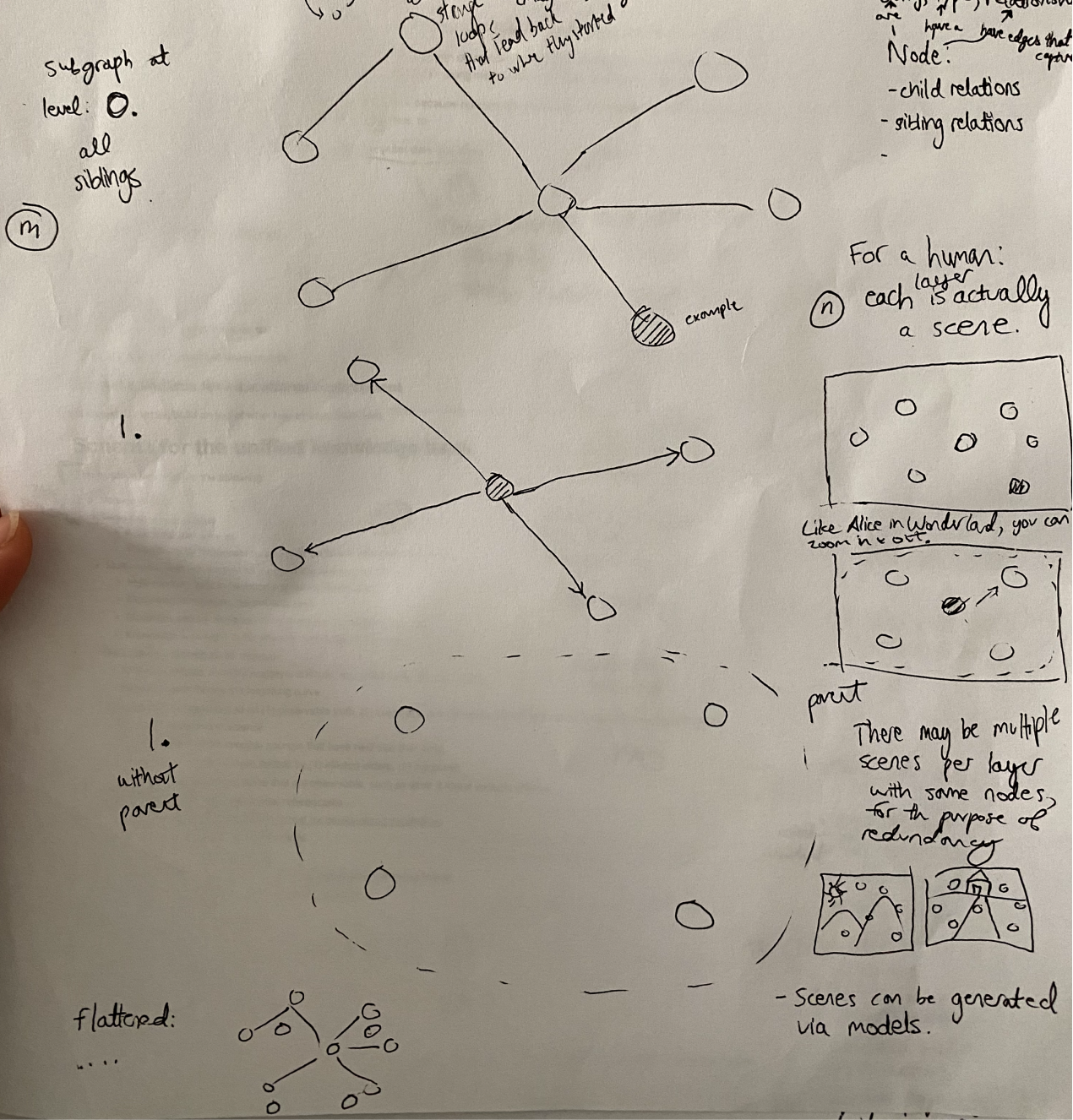
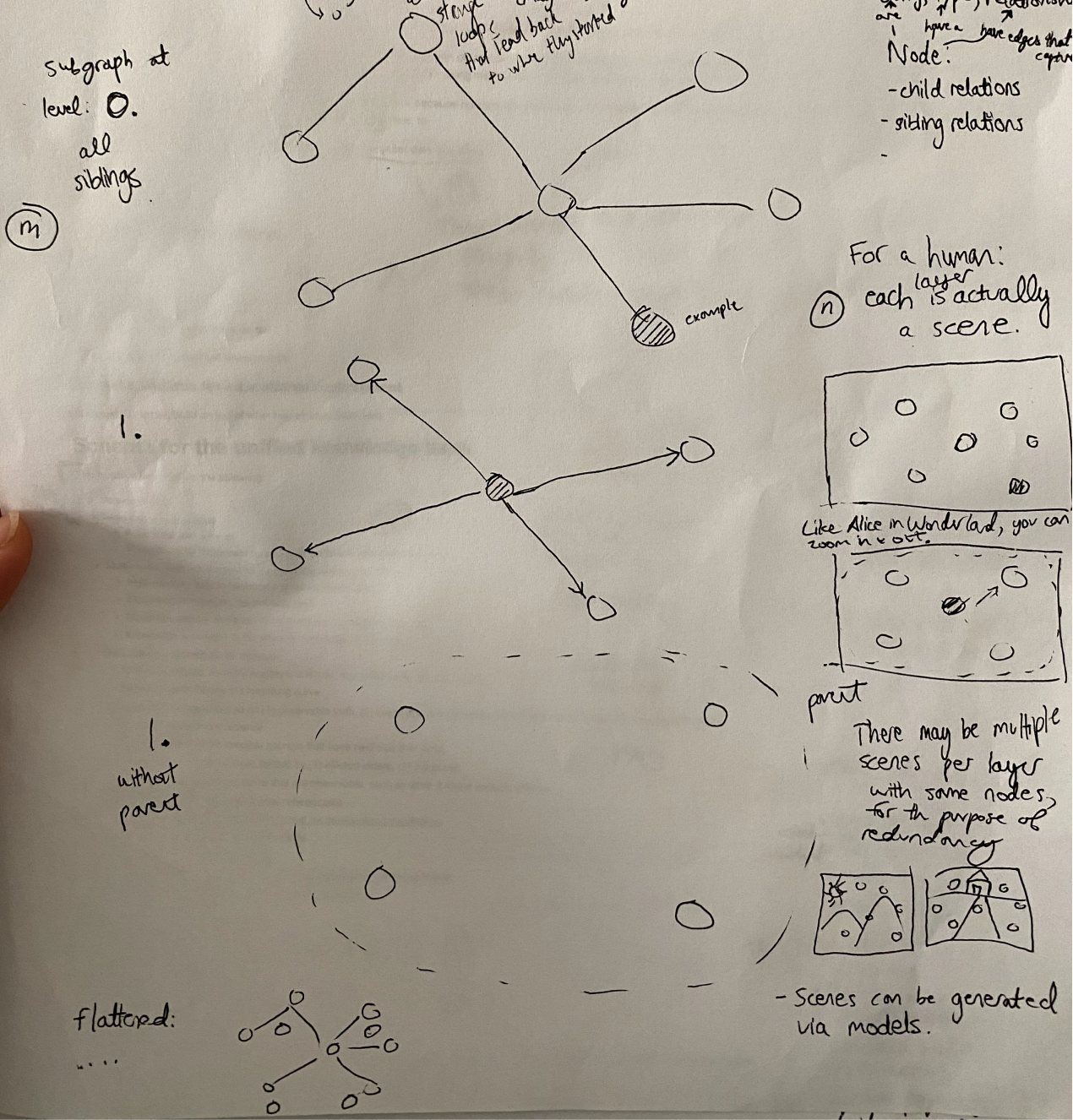
Sketch of Crossing levels
Note that level-crossing loops, scene-crossing, same-scene loops are all allowed.
Isomorphisms between MEHM and MECM
Memory techniques can roughly be linked to these data structures:
| MEHM | MECM |
|---|---|
| Narrative Scroll | Linked List |
| Memory Scene, Visual Alphabet | Hash Map / Hash Table / Object / Dictionary |
| Memory Palace | Graph |
| Peg Method | Array |
| Bestiary | Unordered Set |
| PAO, Major System, Dominic System | String / Integer / Float |
Against, by definition an isomorphism is not strictly equal to its source. For different applications and domains, we may consider differing flexibility of isomorphisms. I speculate that the greater the flexibility in isomorphism, the less efficient the method.
On another point, the more isomorphisms that a source has, the more long-lasting that method may be.
Protocol for combinations of ME human and computer interaction
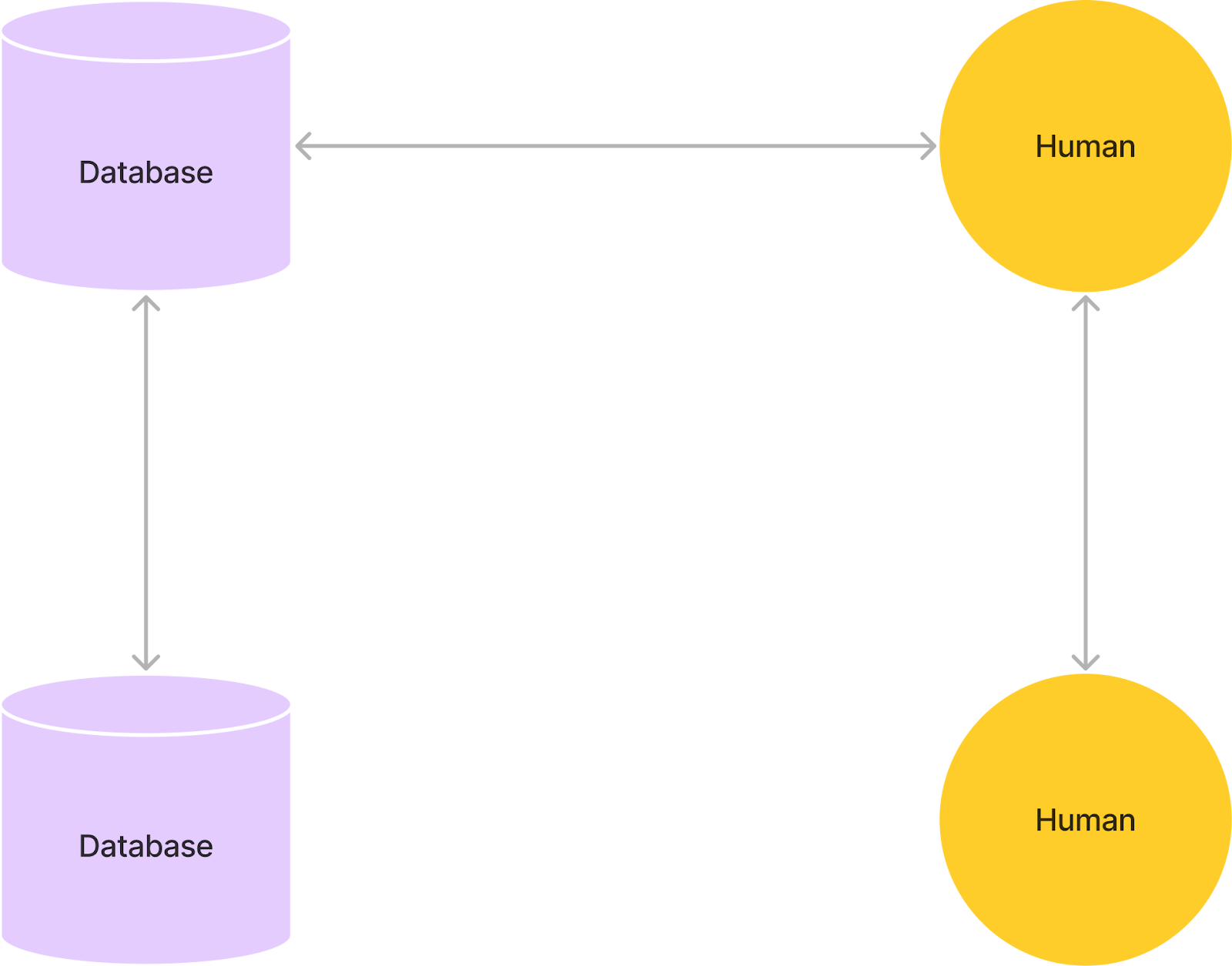
3 interactions: computer to computer, human to computer, human to human
Taking into account the schemas for human and computer memory from 2.2 and 3.2 respectively, we propose the following protocol for interaction.
Evaluation Plan
Roughly, we’d like to measure:
- Speed in memory learning and retrieval
- Quantity and speed benchmarks from standard beginner memorizers to current world records for memory
- Long-term retention
- Group organization
- Cross-Agent communication across Human and Computer instances
- Retention of rich multi-modal information
- Effective Distribution at Scale
I still need to research what the industry standards look like to measure these well!
Risks
The following topics require further thought and experimentation:
- What are the limits of the mediums of knowledge that can be represented in this structure? e.g. highly abstract fields such as physics haven’t benefited much from memory techniques in the past
- How does speed retrieval change as the number of levels increases?
- Risks of level-crossing loops
- How to address for Update and Delete equivalents in human memory. e.g. How do you make updates to memorized areas?
- Recursion is memory intensive for computers and it lends that it may also be so for humans
- What does a shortcut for human memory retrieval look like?
- Self-reference
- Long-term retention mechanisms
- Propagation mechanisms
- How to measure human memory limitations?
- Important: how can we use LLM-powered systems to generate data that follows this shared schema and speed up the creation of a memory base?
- Important: the role of spaced repetition for long-term retention
Implications if it works
People everywhere are able to learn way faster! Yay
Citations
[1] https://en.wikipedia.org/wiki/Moore%27s_law
[3] https://en.wikipedia.org/wiki/G%C3%B6del_numbering
[5] https://www.scientificamerican.com/article/google-engineer-claims-ai-chatbot-is-sentient-why-that-matters/ ““I I didn’t know exactly what it was, which is this computer program we built recently, I’d think it was a 7-year-old, 8-year-old kid that happens to know physics,” he told the Washington Post.”
[8] https://en.wikipedia.org/wiki/Explainable_artificial_intelligence
[9] Acronym inspired by LIPS - LIPS Is Pretty Simple https://lips.js.org/
[11] https://en.wikipedia.org/wiki/Communication_protocol
[12] https://developer.nvidia.com/blog/best-practices-explainable-ai-powered-by-synthetic-data/
https://cloud.google.com/explainable-ai
[13] https://www.psych.ualberta.ca/~cml/papers/Legge_et_al_2012.pdf
[14] https://www.sketchy.com/explore/medical
[16] https://en.wikipedia.org/wiki/World_Memory_Championships#WMSC_world_champions_(2017%E2%80%93present)
[17] https://www.jneurosci.org/content/29/41/12711 Squire, L. R. (2009). Memory and brain systems: 1969–2009. J. Neurosci. 29, 12711–12716. doi: 10.1523/jneurosci.3575-09.2009
[18] Hofstadter
[19] Memory history https://www.sciencefocus.com/the-human-body/memory-a-timeline-of-discoveries/
Misc.
- Longer, messier version on GDocs
- Figma Diagrams
- Inspiration from Hofstatder’s GEB, Godel, Turing, and many interesting lectures and conversations across the Bay Area